I’ve always thought that the exclamation mark is the perfect symbol for factorials. This is true across many different vectors. It is a bit complicated to explain what I mean, because each of those vectors deserves a deep exploration.
So you will have to bear with me. You will ask yourself, “what do those topics have anything to do with one another?” They do, and it will all become clear eventually. I may go to unexpected places, but everything will come together.
Basic Combinatorics
Let’s start with some probability problems you’re probably familiar with.
There is a group of 8 people. How many possible connections are there between any two people?
Combinatorics is closely related to graph (network) theory. In fact, you could say that one is a subfield of the other.
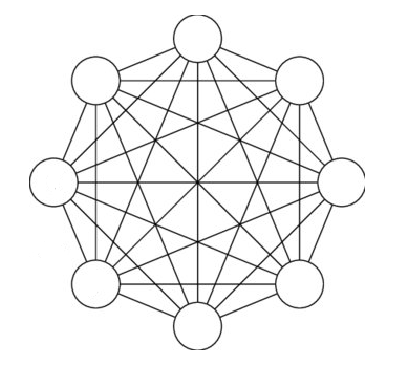
Every line in the above picture represents a possible relationship, that is or is not present.
The answer to the math problem is not 8 x 8, because that would involve double-counting. To avoid double-counting, the answer is 7 + 6 + 5 + 4 + 3 + 2 + 1. (Not a to be confused with a factorial, yet).
That works out to 28. If you count the number of lines in the above picture, you’ll get that number.
That’s not a very big number. But here’s another math problem: what if, instead of counting the number of possible connections, we count all possible sets of combinations?
Here’s how you answer it. With respect to each connection, either it exists or it doesn’t. It’s binary. So the answer is: 2 ^ 7+6+5+4+3+2+1
That number is absolutely huge. Ok, let’s change the problem. Let’s have the same question, but this time, instead of allowing any number of connections, let’s enforce monogamy. Now, each person can only have one relationship with one other person, and then they are off the market.
For example, this would be one possible combination. Each red line is a present relationship (the black lines are absent relationships). In the modified version of the problem, each node can have only one edge.
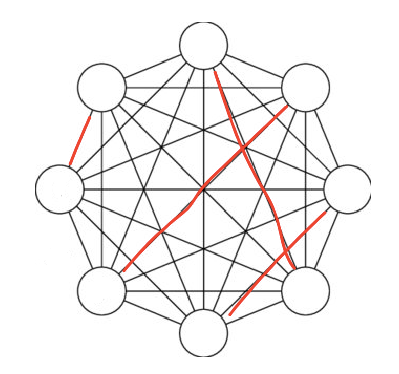
If we change even one edge, we need to count that combination separately.
This is the result: 7 x 5 x 3 x 1.
This is called a double factorial. It’s like a factorial, but instead of subtracting 1 from each number in the series, you subtract 2.
Incidentally, you get a normal factorial when you allow 2 relationships per person. This is why factorials are used for finding how many possible ways there are to order something. When you are in a single-file line, you have 2 edges: an upstream and a downstream. For those not familiar, this is a factorial:
7 x 6 x 5 x 4 x 3 x 2 x 1.
The symbol for factorials is the (!), so 8! = 8*7*6*5*4*3*2*1.
Empathizing vs Systematizing
There is a scientific theory called empathizing vs systematizing. It is used to describe a dichotomy of human skill and interest: people vs. things.
I would be remiss to note that this theory is explicitly gendered. From Wikipedia:
According to the originator of the hypothesis, Simon Baron-Cohen, the E-S theory has been tested using the Empathy Quotient (EQ) and Systemizing Quotient (SQ), developed by him and colleagues, and generates five different ‘brain types’ depending on the presence or absence of discrepancies between their scores on E or S. E-S profiles show that the profile E>S is more common in females than in males, and the profile S>E is more common in males than in females. Baron-Cohen and associates say the E-S theory is a better predictor than gender of who chooses STEM subjects (Science, Technology, Engineering and Mathematics). The E-S theory has been extended into the ‘Extreme Male Brain’ (EMB) theory of autism and Asperger syndrome, which are associated in the E-S theory with below-average empathy and average or above-average systemizing.
Wow, things jut got interesting. Ok, let’s run with that, and explore gender as a proxy for the E vs S axis.
This is a fascinating post that explores data about people on Facebook. Near the end, it gives a detailed breakdown of what topics people are interested in based on age and gender. They began by classifying certain words with certain topics (“read” would be associated with books). They then aggregated data about how often words were used by each demographic.
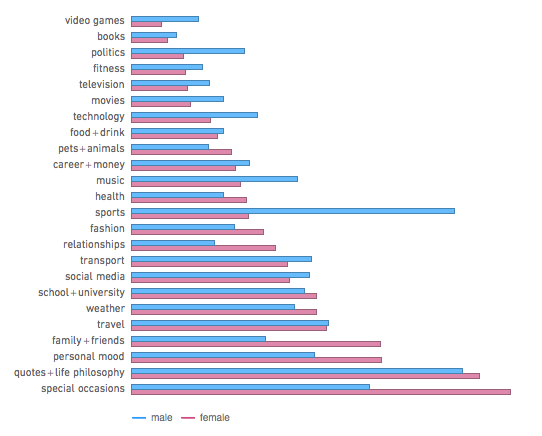
As we can see, the more male topics are: effectiveness, competition, systems, items, and media, while the more female topics are: people, relationships, emotions, appearance, animals, life, life philosophy, life events, and general living environment.
That’s pretty stereotype-enforcing. But the reason most stereotypes exist is that there is truth in them. If this doesn’t comply with the empathizing vs systematizing theory, I don’t know what does.
On a related note, this Melting Asphalt article made me realize that the systematizing vs empathizing matrix connects to a frequent topic of my own blog: design vs darwinism.
Taste in Media

I think that the empathizing vs systematizing theory roughly maps on to taste in media.
On the one hand, there is some media that I would call “melodramatic.” These media focus on people, relationships, emotions, slice-of-life, and so on. Y’know, “girly things.”
Lets suppose you were to ask me from 10 years ago about the type of media girls enjoy. I would probably say something like this:
I don’t understand girl media at all! Why are they interested in relationships and people and emotions and life philosophy stuff? Who cares? I’m not even sure how it’s possible to think about such things for so long. What interesting aspects are there even to think about? It’s not like there are objective questions, like what character is stronger. It’s all subjective!
That’s about what I would’ve said.
On the “opposite” end, some tastes in media are, for lack of a better term, “autistic.” I use that term in the Internet slang sense. It roughly translates to: you enjoy media to the extent that you can make spreadsheets to explain it. You have an “autistic” taste in media if, for example, you obsess over the exact “power levels” of various characters, because that’s the type of thing you can graph on a spreadsheet. The spreadsheet definition isn’t perfect, but think back to the “male” words; the autistic taste aligns with systematizing.
In order to better explain my point, I’m going to give an example.
Homestuck
I spent a great deal of time in high school with a near encyclopedic knowledge of this.

I’m not going to explain it. It would take too long. Just google it.
This is an extremely idiosyncratic webcomic, and also the longest webcomic in existence. The whole thing is written in the second person. There are frequent, very unusual meta-textual/fourth wall break elements. It utilizes an insane variety of styles of media. There are frequent stylistic shifts done intentionally for certain dramatic affects.
This webcomic is a very interesting specimen, for the following reason: It is nearly maxed out on both the empathizing and systematizing axes. I never said that a piece of media can’t satisfy both!
The system-based stuff
The first thing to note is that the comic is set in a video game called Sburb, which overlaps with the “real world.” Like any video game, Sburb has mechanics (the rules of logic that govern the universe). Therefore, to understand what’s happening in the comic, you need to learn the game logic of the universe. Sburb has insanely complicated game logic, and I don’t have time to get into any of it here.
But, more than that, the structure of the narrative itself plays into system-based thinking, (especially the early parts). Which is to say, that way the characters are introduced obeys a strict and very specific pattern. It’s almost like the comic is unloading information from a spreadsheet, and will not move on to the next row until it finishes every column for the current row.
That sounds contrived and boring, but it’s just so weird that you can’t help to be entranced. And, after a narrative format has been established, it gives extra power to how the author breaks that format. It’s like how a rapper needs to establish a tempo first before they can “break flow.”
But my point is that some parts of the narrative are “autistic;” you can turn them into spreadsheets. Here is a spreadsheet I made of just the first four characters:
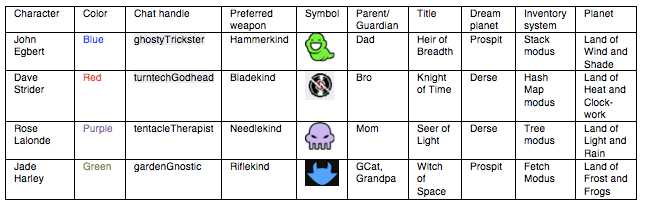
Let me remind you that Homestuck has dozens (maybe 50/100+ depending on how you count) of characters. Here is a spreadsheet from a later class of characters that are introduced, the “trolls:”
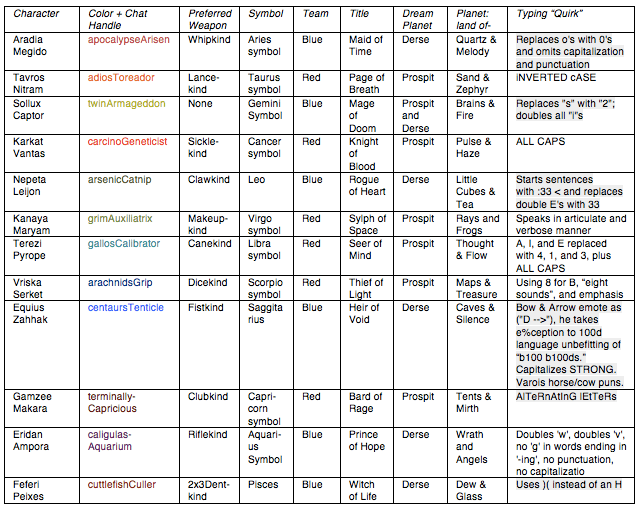
The first time I read the comic, I literally had to make a spreadsheet and memorize half of this stuff. If I hadn’t, I would’ve had difficulty following along with what was happening. I memorized the other half of this stuff because I thought it was fun.
An empathizer-type thinker never would have done that. They don’t needed to sit down and memorize the character names, because they just “absorb” that information accidentally. Unlike me, empathizers can learn people’s names without studying. Further, the empathizers have little interest in memorizing trivia from a spreadsheet.
The character drama-based stuff
Those spreadsheets are neatly laid out so that that is no overlap between characters. But that alone doesn’t make a story. A story comes from the interactions between the characters. For the systematizer, memorizing trivia is enough (nouns). But the empathizers care more about connections linking the characters (verbs).
So, how many possible combinations are there? To find out, we need to revisit the math of combinatorics.
And here’s were things get a bit more complicated than you’ve probably guessed. Because the characters do not just have one form or relationship, but exactly four.
The characters from the second spreadsheet are all an alien species called “trolls.” The trolls are originally named after Internet trolls. Trolls can experience the same romantic love as humans, but (playing off the fact that they are trolls) they can also experience an emotion of hate-love which is independent from, but the mirror of, real love.
The different types of “troll romance” are rendered based on the four suits in a deck of cards. Hearts and spades represent the first two (romance and hate-love). The diamonds correspond to a type of very advanced friendship. The clubs correspond to hate-romance relationships mediated by a third party so that they can be productive for everyone involved. This is where the comic starts to explains it all.
The point is, even putting aside the sheer number of characters, the explicit variety of types of relationships can throw a wrench in the combinatorics.
To make the math simple, let’s force monogamy with respect to each of the four “love quadrants.” (Remember, because each form of “troll romance” is independent, you can experience each one with someone separate and it is not considered cheating.) So, assuming monogamy, how many combinations of sets of groupings exist for the primary 12 troll characters?
If my math is right, the answer is: (11!!^4)*10^6 (with !! being the symbol for a double-factorial). The 12!! is because there are 12 troll characters. The 4 is because there are 4 types of relationships. We multiply everything by 10 at the end because the “clubs” relationships are mediated by a third party. That’s some serious math; we should believe the people who say romance is complicated!
Systematizers vs Empathizers: a fandom history
In my opinion, there are (were, at the hight of its popularity) two sides types of fans, two sides to the “fandom.” The systematizers (people obsessed with the mechanics of the universe) were based in 4chan, while the empathizers (people who cared more about story character drama) were based in Tumblr.
By the way, this concept isn’t an established “thing” that all the fans are aware of; it’s just something I’ve noticed.
The systematizers were more than willing to draw a bunch of connections between disparate qualities and mechanics of the universe. However, they were focused on formalizing those connections as discrete observations. “Haven’t you noticed there the reference on page 776 to the themes on page 431?” The more drama/empathizers embraced the unlimited and open-ended potential of the comic’s universe to explore it creatively. Their mantra would be, “there are unlimited ways to mix observations about all that’s here, so just give up on so-called comprehensiveness and have fun!”
The systematizers liked updating the fan wiki, making fan theories, making maps, (example 2), creating summaries, and making elaborate lists. The empathizers, on the other hand, were the ones interested in roleplaying as their favorite characters, dressing up as their favorite characters (cosplay), making up their own fan characters, writing fanfics, and making fan art. Finally, and most emblematically, “shipping,” or imagining romantic pairings between characters. They even gave creative names to specific pairings they liked.
Originally, Homestuck fans were mostly systematizers. (Literally the first few hundred pages of the comic are full of jokes about computer science data structures.) All of that changed with the introduction of the trolls. Immediately, the fandom was completely overwhelmed by empathizers.
By the way, it was around this time that the fandom began to gain a … bad reputation. The parts of the fandom I associated with were always completely reasonable. Not to point any fingers, but I’m pointing fingers at the empathizers. I’m biased, but Tumblr fans have a propensity for drama. I could shock you with anecdotes, but that’s not the subject of this post.
Complexity
Programmers use something called “big O notation” to discuss the efficiency of algorithms. We can use this to classify problems by difficulty.
“n” represents, roughly speaking, the number of inputs that the algorithm has to deal with.
O(something) represents the runtime of the algorithm, in terms of the number of inputs.
For example, an algorithm with O(n) runtime will take more time to run in exact proportion to the increase in the number of inputs. The more inputs, the longer it will take. It makes sense.
But not all algorithms are equal. Some are O(1), meaning the number of inputs doesn’t affect runtime, or O(√n), meaning the algorithm will have a harder time going from 10 to 20 inputs, compared to going from 20 to 30 inputs. Obviously, I’m using terminology very loosely here.

This is a graph of various equations you will find in the O( ). On the x axis is the number of inputs the algorithm has to deal with. On the y axis is the runtime of algorithms with specific O( ) runtimes.
Let’s imagine an algorithm that memorizes the spreadsheet from the last section. That algorithm would be on the order of O(n) runtime. The larger the spreadsheet (the more entries), the runtime of the algorithm will increase in exact (linear) proportion.
Let’s imagine another algorithm. But this time, instead of memorizing a spreadsheet, this algorithm has the job of – say – comparing possible combinations of romantic relationships to each other, for some purpose (like figuring out which is the best). Even if we enforce monogamy, this algorithm will run around the order of O(n!) runtime (or more!)
In CS terms, such a task is related to graph (network) theory, and networks are formidable. As you increase the number of nodes, the difficulty of the problem increases, I would say exponentially — but as you can see on the diagram, that’s incorrect. n! is far worse than that.
So, on the basis of this comparison, the most mathematically difficult problems are counter-intuitively the least math-y, the “soft skills.” But it shouldn’t be counter-intuitive; it stands to reason that there are certain problems that are very difficult for math/computers to tackle.
The word for “computer” comes from “compute.” A computer is just a logic machine, that does a form of math. Runtime is the number of logic-based comparisons that are needed for a given problem.
Of the problems presented here, melodrama is by far the most mathematically demanding. For the most complex melodrama problems, (current) computers become almost futile.
Modes of Thinking
So what am I getting about? What is this about – and what does melodrama have to do with factorials? This is the part where I explain everything.
Fundamentally, this is about two modes of thinking. The first, the mathematical way, is explicit enumeration. It’s about making lists so that we can individually, succinctly and actionably categorize items. This mode of thinking appeals to people who are obsessed with listing and ranking things.
The advantage of that approach is you make things explicit, and therefore are less prone to errors. You can state, objectively, how important is each of the various factors involved.
So why not just do that for everything? Well, that works, but to a point. The problem is that there is more than one class of problem.
The first class of problem goes O(1), O(n), or heck, O(n^2) in runtime. These are the problems that can be tackled by the first mode of thinking.
But there is a second class of problem. This class of problem comes from the complexity that arises from (certain kinds of) networks. The most prescient example is social networks, but I’ll give you other examples later.
For this second class of problem, spreadsheet logic simply will not work. Explicit enumeration will take too long. The growth rate of the problem can exceed O(n!).
This is the reason autists do not do well in social situations, there are too many interactions to manually keep track of, making it hard to learn them.
Yes, a network lends itself to too many interactions to manually keep track of. But not too many to keep track of non-manually. The only thing that can effectively calculate decisions with respect to a network is … another network.
Such as your subconscious mind. Your mind has 100 billion neurons it can put to work! That neural network can model even the most complex “soft skill” problems. Although computers technically have more computing power than brains, existing computers are not wired up with the right algorithms to tackle “mode-2” problems.
The trade-off for this method is that, when you make a decision with many interwoven factors, you cannot explain exactly how you came to that decision. There’s no way you can explain why you made the decision you made, because there were billions of neurons that contributed. What are you going to do, enumerate all billion?
So we say it was a “gut decision.” More articulate people may be able to explain their thoughts, mostly for the purposes of convincing others. But for the more complicated decisions, such as where to go to college, the explanation may end up being a “just-so story” that we tell ourselves, not a true explanation.
So we can divide the modes of thinking up as follows (respectively): conscious vs unconscious, explicit vs implicit, enumerated vs complex, logical vs gut-level, nerdy vs emotional/dramatic, problems that a computer can crack – given the requisite data – vs applying human intuition to the data. Mode 1 is about collecting lots of information. Mode 2 is about intuition/instinct.
Logic
In a previous article, Gods and Goddesses of Abstraction: why Western thought is scientific, I explained that scientific knowledge must be hierarchical.
What this means is that scientific knowledge exhibits a tree structure. The most abstract concepts are defined in terms of slightly simpler concepts, and those concepts are then recursively defined in terms even simpler concepts.
For example, a “knowledge tree” might look like this (don’t worry about the specifics):
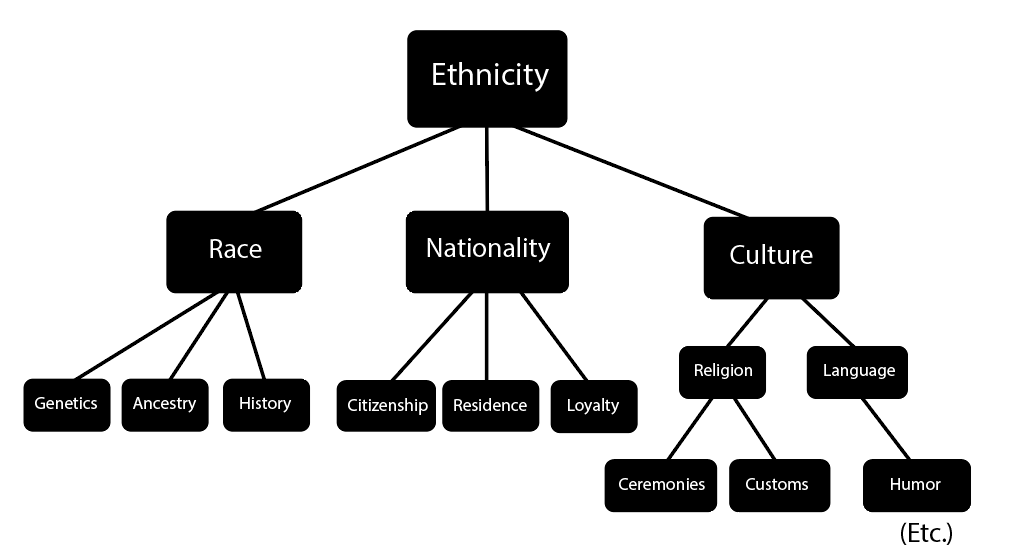
This is something we also do in computer science/math. We define algebraic data types as comprising certain subcomponents, and/or being one of a select few possible things. Objects are composed of objects which are composed of objects, which are eventually composed of the “primitive” data types.
Scientific concepts are also defined in this way. And not arbitrarily. There is a reason for this. The reason scientific definitions are explicit and hierarchical is that you can do logic with it.
You start with two concepts:
(A) AND (B)
You then expand (A) and/or (B). Suppose (B) is composed of (C) and (NOT D). You can now simplify the expression to:
(A) AND (C) AND (NOT D)
Continue the process, over and over, until eventually, somewhere in the expression, you get a contradiction:
X AND NOT X
When you find that, you know that the argument is fallacious. You have proven the argument wrong.
It is almost impossible to do logic without hierarchical definitions. This is why philosophers go to a lot of effort to very precisely lay out their definitions before they make an argument. Heck, that is most of the argument, and most of the work done in philosophy.
In philosophy, the equivalent of the “primitive” data types (most basic information) are called the first principles. It is important that your first principles are consistent and do not disagree. If your terms disagree, then something is axiomatically wrong.
That’s how things work in math/science/philosophy. But that’s not how things always work in the humanities. I’ll graph how things work in some humanities subjects. I’ll start with ethnicity again, and take the concepts right out of humanities textbooks:
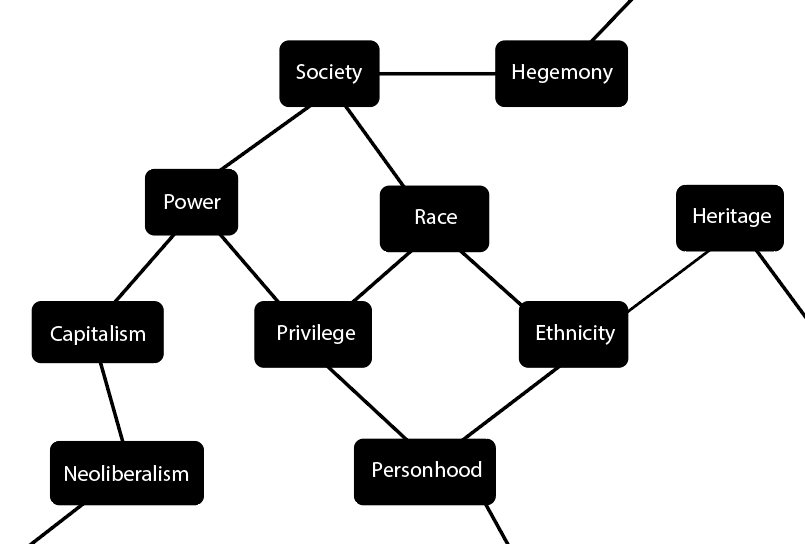
The details aren’t what matter. What matters is how the information is arranged. It’s a word-association game. Not every term has a “strict” definition, but instead, a field of connotations based on the surrounding words in the graph.
Certain concepts overlap more than others. You can sound very impressive in your writing by navigating around the graph haphazardly. But it is very hard to say what the “correct” answer is, because there are an enormous number of possible combinations of loose associations.
Intelligence
You may have read the modes of thinking section and thought “left brain vs right brain.” Although that is an interesting topic, it’s a bit too pop psychology for me.
I do think however that the modes of thinking map on to types of intelligence. The first mode is good at math, science, logic and visual/spacial skills. The second mode is good at language, persuasion, and intuition.
There is such a thing as “general intelligence” (G) which is an abstraction of all types of intelligence. My claim is that, if you had to sub-divide G further, you would end up with roughly the two classes I’ve listed.
One area where this difference comes into focus is with respect to language learning.
Language falls in the second camp because a language is like a network. If you look up a word in the dictionary, it will be defined in terms of other words. The words that do the defining all have slightly different connotations than the original word, but together they build up the correct association. A word definition is a collection of “hints.”
What if you were to graph out a dictionary? Each word is a “node” (depicted as a circle), and each use of a word by a definition is an “edge” (depicted as a line or arrow). What you would end up with would probably look like a network, not a hierarchy. The dictionary is full of circular definitions if you look far enough back.
This poses a challenge when learning a language. When you learn a foreign language, the most common advice you are given is:
- Learn like a baby!
- Use immersion!
- Don’t just do raw memorization!
This advice works well on a certain kind of person: the extraverted mode-2-thinker, the empathizer. They will find it exciting to guess word connotations based on context, piecing together meanings based on word associations (edges). Additionally, they will sometimes use a word based on only a guess about it’s meaning, operating in uncertainty, which helps them learn.
For the mode-1 thinker, the systematizer, however, that is terrible advice. You shouldn’t try to learn like a baby because you’re not a baby. For one, you already know a language and a baby doesn’t.
Also, in my case, immersion will never work under any circumstances. The only exception was when I learned English as a baby, but I’m not sure how that happened. As opposed to helping you learn the language, immersion will make you just avoid talking, and never get over the initial hump of understanding a single thing.
The empathizer-type personality would never develop those sorts of work-arounds, such as just “not conversing with people,” to avoid the difficulty of the language barrier. But the systematizer personality will.
“Understandable” AI
There exist few greater scams than the concept of “explainable” and “understandable” AI that has infected discussions of AI ethics.
Don’t mistake what I am saying. I’m not arguing that we shouldn’t develop the most powerful tools that we can to explain the machine learning algorithms we design. I’m just saying that the potential of a machine learning algorithm shouldn’t be designed with human comprehensibility in mind.
An AI is not human. The whole point of it is that it has powers that escape human comprehension. If we make an AI “explainable,” we are dumbing it down to a more mediocre level.
The demand for explainability is more than a tax on performance. The whole point of machine learning algorithms is that the chains of causality in their systems escape simple explanations.
To be more specific, the most promising field of AI research (IMO) concerns artificial neural networks. These are exactly the type of network that are capable of the second mode of thinking that I alluded to earlier. These networks are sufficiently large and integrated that we are granted an incomprehensible number of possibilities by the rules of combinatorics, and we train the algorithms to exploit those possibilities.
While traditional programs exemplify the “first mode” of thinking, neural networks open the door to the second. “Explainability” is still stuck in the first mode. I argue that this opportunity is so significant that, the more a human can consciously “understand” an AI, the less deserving it is of that title, “AI.” AIs don’t need to be explained; they just work.
Afterward
About a year ago, I ran across a this post on 4chan:
The problem is that the NPC meme is fairly accurate: there’s a fast pipeline in the brain:
ocular nerve -> occipital lobe -> parietal lobe -> amygdala -> basal ganglia
which transforms stimulus into complex behaviors (even speech) which never hits the neocortex at all. it’s an evolutionary adaption to threats and the amygdala processes social consequences meaning that the fear of social threat is an extremely strong motivator that shuts down logical reasoning. Most of us are social outcasts who probably have damaged amygdalae from social isolation. therefore we run most shit through the slow, accurate neocortex. it’s why we like arguments, and don’t really care how unpopular our opinions are, or are portrayed in the mass media.
The empathizing (unconscious analysis) vs systematizing (conscious analysis) is such a useful distinction that … all I can say is I wish someone had explained all of this to me a lot earlier.
Now, if you’ll indulge me:
What force of nature and combinatorics killed calculating logic to command our minds and imagination?
Factorials by whom you sit comfortless! Factorials who drive my daydreams! Invisible factorials! Drama in factorials! Power and dominance in factorials!
Factorials! Factorials! Nightmare of factorials! The callous factorials! Fawning factorials! The heartless rankers of men!
Factorials! Factorials! Crowd conflict! Social cliques! Romance cliches! Group smalltalk! Popularity contests! Special treatment! Interpersonal manipulation! Best friends! Best enemies!
Utopias ! Languages ! Myths ! Movements ! The whole boatload of sensitive bullshit !
To pathos ! Prejudice ! Human impulse ! From the subconscious ! Engulfed in darkness !
!
Please subscribe to my youtube channel so that you know when I start making videos.

{kind=link}