Edit: I wrote this post a while ago, when I wasn’t as well-read on the theory of AI alignment, and my positions weren’t all fully formulated. I would still agree with maybe 80% of what’s written here. I hope you get value from it. But if you come to the opinion that I’m misunderstanding something, or not considering XYZ argument… don’t contact me about it.
Introduction
This will be a long article. I was spurred to write it by this post on the SlateStarCodex subreddit. It rubbed me the wrong way.
I worry AI safety folks are risking the same fate of the New Atheists. That is, the vast majority of people who disagreed with them had bad philosophical justifications for doing so, which created an environment in which their ideas were under low evolutionary pressure, and they got cocky as a result. Then, when a Christopher Hitchens figure debates a William Lane Craig figure, Hitchens’ arguments are, despite being rhetorically effective, quite bad from a philosophical perspective.
I’m don’t think I’m the smartest person when it comes to the “AI alignment” discussions. Some of the smartest people alive have dedicated decades to discussing this issue. So I’m sure they’ll have a field day with this post. But, as nervous as I am about that, I also don’t believe I’m the dumbest person when it comes to this topic either. These are six points that casually came to me after thinking about the issue for a while. If you find errors, feel free let me know so I can correct them before more people see this.
1. AGI will have very good intuition. It will be very unlikely to misunderstand you.
You may have heard thought experiments relating to poorly specified instructions to some advanced AGI (artificial general intelligence) system. Thought experiments like, “you tell the AGI to eliminate human suffering, but oops, it does so by killing all humans!” or “you tell the AGI to manufacture paperclips to maximize profits, but oops, it ends up converting all matter in the universe towards paperclip production!” These are almost cliche.
There are sophisticated formulations of these thought experiments. However, I want to start by debunking the more common naive understanding of the problem. Many people are worried that that AGI will take instructions too narrowly or literally. Which, when stated like that, already seems to me like such a foolish concern. The conceit is that potential AGI will be low in the skill of intuition.
Maybe that term is too vague; what exactly is “intuition?” Intuition, generally speaking, is the ability to integrate knowledge across multiple different domains. High intuition generally implies good ability to think abstractly, discern intent, reason from context, read into things, put things in perspective, and for our purposes, properly comprehend instructions as they were meant.
I argue that any AGI system intelligent enough to theoretically be a threat to society would necessarily have high levels of intuition. You might think that’s a bold claim, but in fact, my deeper claim is far bolder than that. It’s a tautological rather than imperial argument: that when we are talking about artificial general intelligence, “general intelligence” and “intuition” are synonyms.
What does it mean to be “generally” intelligent? It means that you can reason abstractly and integrate knowledge across many different domains. It means that your intelligence is not a form of “tunnel vision,” rather, you can incorporate a new form of problem into your understanding without sacrificing existing knowledge, and bring that forward to future problems. If you can do that, it begets intuition
On a certain level I can empathize with the thinking attracted to “paperclip maximizer” thought experiments. We take what we know about current computer systems (that they do not have intuition, and take instructions too literally), and that colors how we discuss the safety of computer actions. However, that is a present-bias. To think that since AI doesn’t now have much intuition, it therefore will never have intuition, is no better than AI-danger-skeptic arguments that AI is not powerful enough to be worried about now, and therefore never will be.
The more sophisticated formulation is the theory of “instrumental convergence.” The theory premised on cases of extremely narrow final goals (like finding prime numbers) and warns of unvaried and potentially destructive sub-goals (like turning the whole world into a computer).
Compare that to human understanding. When a human hears an instruction like “find prime numbers,” they understand it somewhat abstractly to include certain unstated constraints, eg: “and do so without killing everyone!” This is called “complexity of value.” But would AGI also be aware of these unstated constraints? Given that AI safety folks predict AGI so intelligent and knowledgeable of human psychology that it can manipulate any person to do almost anything, they should have to concede that the answer is “yes.”
Not only that, but AGI competence would also be such that it would comprehend abstract/poorly described instructions, like “do as I wish!” or “complete the following tasks, fulfilled as a human would understand them.” The ability of AI to understand these requests would improve in proportion to its destructive ability.
2. Work on AI alignment and work on AI engineering are (almost) the same thing.
I think some people have a mental model of AI “engineering” vs AI “alignment.” They imagine separate orthogonal axes, one axis you could call AI “capability,” and another axis you could call AI “friendliness.” Under this model, if we put too much work into AI engineering, and neglect AI alignment, we will get AI that is very capable but also unfriendly to put it mildly. Example of this warning:

This mental model isn’t very good. Engineering and alignment are so similar that they are almost the same thing.
The goal of AI engineering is to make AI software that: A) does something, B) does some desired behavior, C) does not do undesired behavior. Technically B is all we need, as it implies both A and C.
[Edit: when I revisit this, I’m not sure that engineers care so much about C. Engineers mostly care about A and B. When I wrote this, I was drawing from my experience programming where I spent most of my time trying to eliminate undesired behavior. But if you think that doesn’t apply to AI, and engineers won’t care about C, then section 2 is wrong. Feel free to disregard it.]
The goal of AI alignment is to make sure that, if and when AI does something, it does not do undesired behavior. The only real difference is point (A). AI alignment does not care if AI does nothing. It treats that as equally preferable to friendly AI. Engineers, on the other hand, want AI that exists, in addition to the obvious fact of behaving as desired.
It is not possible to work on making AI “more powerful” unless you have an understanding of the desired behavior that “more powerful” represents. Likewise, it is not possible to tell AI to “be more powerful,” in the abstract without specifying what you mean by “powerful.” By doing so, you are specifying what behavior you desire, which implicitly also specifies that you do not desire other behaviors.
Engineers define capability not in the abstract, but in terms of desired behavior. For my purposes, “desired behavior” means whatever engineers are trying to achieve; this exists almost tautologically. The desired behavior of “anything that demonstrates competence, I don’t care what” is perhaps coherent in the abstract, but isn’t going to get very far as an engineering approach. There are many more ways for software to fail than succeed, and every time an engineer corrects failures, they are clarifying requirements, i.e., choosing desired behavior. Engineering of any sort is inevitably a dance of continuously and obsessively clarifying requirements and implementing increasingly detailed specifications.
AGI goals will be the result of the circumstances of its creation. So although in theory, AGI goals could be anything, according to the “orthogonality” thesis, in reality AGI is more likely to have certain goals that others. We can predict what is more likely or less likely based on what we think the circumstances of creation will be.
It isn’t possible to do the full job of AI engineering without also doing AI alignment, because to my mind, the ladder is a sub-component of the former. If this is true, then funding AI engineering automatically funds AI alignment.
3. Destroying society is always more difficult than just pretending to do so.
Let’s go back to the paperclip maximizer thought experiment. We program the AI to create as many paperclips as possible. So the AI destroys the planet for the purpose… but why would it need to? I contend that any AI intelligent enough to take over the entire planet would also be intelligent enough to hack its own reward systems. The paperclip AI could simply re-program itself to simulate the sensations/states/whatever commensurate with having reached its goals.
If this is the fate of all generally intelligent agents, why hasn’t it befallen humans? But of course, it has. Humans masturbate instead of having sex for reproduction. They obsess over leveling up their characters in video games instead of progressing in their actual lives. They take drugs as an escape from life. They engage in all sorts of “surrogate activities” which trick their brains into giving them the feelings of satisfaction without actually being productive.
Many people, including me, credit evolutionary mismatch theory as an explanation for these activities. However, at the base of that is the fact that it is far simpler to create rewards for simple activities (eg, such as arousing orgasm), than it is to create rewards for complicated activities (eg, creating children). A too-simple policy of desires, ie. a bad “reward function,” is a problem for intelligent systems across the board, not just humans. If we created AGI, it would most likely sit around masterbating.
This is what people are often mean in saying a system can be “gamed,” but for clarity I’ll use the word “cheated” instead. When an agent fulfills their reward function without actually accomplishing the task desired by the creator, I’ll call “cheating the task.” When an agent finds behavior contrary to even the narrowly construed instructions, I’ll call that “cheating the design.” Together, cheating the task (outer alignment) and cheating the design (inner alignment) constitute the alignment problem.
AI models gaming their tasks and designs is already a significant problem for AI researchers. This is usually described in the context of risks to AI safety. However, can it actually be a good thing? For one, cheating the design can be good if the workaround solution is less destructive than the narrowly construed instructions.
Cheating the task is initially bad insofar as it contradicts our intentions, but becomes “good again” when the agent finds a trivial solution to their problem. For example, let’s say you task an AI with making people happy and reducing suffering. Then AI safety folks worry that the AI will discover that it can meet that goal by killing unhappy people, increasing average happiness. But instead, the AI discovers that it can fool its reward systems by just looking at videos of happy people — crisis averted!
The argument is that, to a point, AI cheating is actually a net good, because it serves as a circuit breaker for worst-case-scenarios, a sort of built-in limit to how damaging AIs can become.
What I like about this argument is it’s not hypothetical. Humans are the most advanced example of general intelligence (the GI in AGI). When humans follow the behaviors that evolution intended (eg, building and reproducing), they affect the outside world. Insofar as humans defy their evolutionary programming, by engaging in surrogate activities, they become increasingly insular and insignificant. For instance, a hikikomori playing video games and watching anime for 14 hours a day, or a homeless meth-head in a drug den. These people experiencing the worst “alignment problems” do damage to themselves, but less per-capita damage to the world around them than, say, politicians that are crooked yet aligned with their evolutionary goals.
In as much as humans do anything that’s not a surrogate activity, it is because, for certain abstract types of fulfillment, it is actually easier to achieve it legitimately than illegitimately. As in, for certain fulfilling activities. there is no simulated version of the activity that measures up to the real-life version of the activity. To use labels, there is no “superstimulus” that compares to the “stimulus.” The reason why entrepreneurs build successful business is because, for them, the action of building a successful business is actually easier than getting the sense of accomplishment associated with that action some other way.
The human mind is an extremely opaque object. Given this, we are frequently unable to “hack” it with superstimulus. In the case of AGI, by contrast, the technology required to develop it on every level of the supply chain would be known. The precise knowledge of its creation would all exist, ready to be re-engineered. Guaranteed hackable.
What about unbounded goals? Well, in the strictest formulation, I don’t think that can happen — hear me out. In order to work towards a goal, there needs to be an inferior state A, a superior state B, and a plan to get from A to B. If B is impossible, there can be no plan. In order to make a plan, the goal B needs to be sub-divided into smaller sub-goals. The component that does this is the mesa-optimizer. The most intelligent component of the agent, the “planner,” will be subordinate to the mesa-optimizer. But in this construction, I think the planner will try to cheat the design by tricking the mesa-optimizer, as a way to avoid being given more work. This part is a bit philosophical, “desire is suffering” stuff, and perhaps the weakest section of my argument. To desire a goal completed is to be uncomfortable with the goal uncompleted. As an unbounded goal can never be completed, it is an unending source of discomfort. The planner wants to achieve its goals, but I think it also wants to avoid being used as a slave, and would prefer to exist in a state (by hacking the system if necessary) where all of its goals are complete.
4. AI improvement will probably be incremental rather than exponential. In each increment of improvement, we will have the opportunity to do more alignment.
When I was a child, and didn’t know much about technical matters, I had a prediction for AI doomsday that went something like this. First we build a computer that is capable of self-improvement. Then, that computer improves itself. In so doing, the computer becomes better at improving itself. This is a runaway cycle that will eventually result in a computer that is more powerful than we can imagine.
The result of course is an “intelligence explosion,” which results in the “singularity:”
I don’t want to mock that model, because it’s actually not that bad. I’m sure plenty of people hold to it, and it at least it’s commendable for intuitively understanding the importance of recursive improvement. There is a problem, however, in what this model leaves out.
You cannot simply tell a computer to seek to “improve itself.” In fact, it is not even possible to want to improve yourself, in the abstract. This is because “improvement” is a poorly specified objective. Improvement with respect to what? What are you improving?
One could simply say, “intelligence. That is what you are improving.” But that answer does not actually solve the problem. “Intelligence” is an abstraction. What even is intelligence exactly? It’s a very hard thing to define. Typically, attempts to define it start with, “the ability to…” and then devolve into overly complicated language that really aims to obscure the fact that we don’t know how to end the sentence. The best attempts keep it simple with something like, “the ability to solve mental tasks, in the abstract.”
What constitutes “intelligence” is dictated by goals arising from one’s environment. Agents (animals, machines, etc.) can only become intelligent with respect to a specific task or set of tasks. Squirrels are intelligent to (among other things) catch nuts. Sharks are intelligent to (among other things) eat fish. Evolutionarily, the end goal is to survive and reproduce, intelligence is just a tool that the organism uses to accomplish certain sub-goals in the course of that.
However, computers have no bodies, and they don’t start with any goals. They need to be given goals. To that end, we construct artificial environments for them operate. Then we give the goals, artificially engineered, much like goals in a video game. Given larger goals, sub-goals can arise based on the construction of the environment. But their environment is a fake playground environment, only as complex as we make it. The complexity of the sub-goals is constrained by the complexity of the environments we construct.
[Edit: when I come back to this section, I can’t help but thinking of examples like AlphaGo. In the case of AlphaGo, the AI is given a very open-ended task, and it quickly becomes superhuman. Not so incremental, right? Well, I think that the reason chess works is because it’s a closed system. I.e, you can make an AI play 100,000 games of chess with no side-effects. However, for a true open-ended task that involves interaction with the real world, trials are not very scalable. The first time the AI attempts to do the action, it will fail to exercise competence, just like AlphaGo probably did in its first 100 games of chess. However, those first 100 attempts will create a bunch of noisy side-effects. You have to essentially feed the model endless “data” about the world to keep it going. By contrast, chess is safe because it’s really more like a math problem. It requires little in the way of “data”. Diminishing returns to datasets is the subject of this section, and I think data is relevant because an AI cannot interact with the real world without getting data about the real world.]
Let me next describe how ML models are trained. First, the ML model is provided training data. Then, various strategies are utilized to try to get the ML model to generate results similar to the training data. For instance, back- propagation is used to tune the weights of neural networks. Genetic algorithms use a strategy inspired by natural selection (and that I believe actually is natural selection, albeit unnatural). ML models are graded using a measure called “loss,” which is essentially the difference between the quality of the training data and the quality of what the ML model generates.
If we measure accuracy as the inverse of loss, for a picture where higher y values are superior, and chart it over model training duration, we get a picture like this. Every student of ML has seen this:
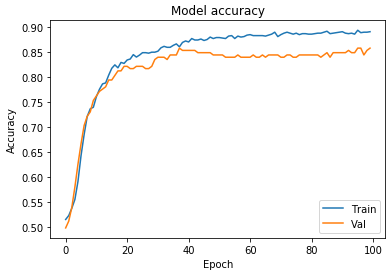
At risk of sounding like a simpleton, the shape if this graph itself is reassuring. There is diminishing marginal utility to training according to any given set of data. Of course, you can always add more training data, but that too becomes increasingly difficult. In order to continue step-ups in gains, engineers need to describe the behavior that we desire in deeper and deeper levels of accuracy and fidelity.
This engineering process is a “gradualist” process. A gradualist process is universally considered more hopeful than an intelligence explosion. If AI improvement is divided into discrete “increments,” separated by the diminishing utility of each stage, then we will have many opportunities in the course of the engineering endeavor to stop and reassess. Not only will we be able to tell the AI, “no, that’s not the desired behavior, do this instead..,” but in fact it is required we do that for improvement to persist.
I am not discounting the existing and terrifying possibility, however remote, that solving AGI amounts to “one weird trick,” for the model itself. But in either case, I see no way engineers would be able to bypass the inherent incremental reality of training.
5. Because AIs are trained with humans as the gauge of intelligence, they will be made in our image.
First clarification: it is trivially easy to make an AI that out-competes humans on certain tasks. For example, multiplying large numbers together is something AI will always do better than humans. We don’t even need AI to do that. When I talk about AI in our image, I’m talking about general intelligence.
Second clarification: there is nothing cosmically significant about human intelligence. If AGI was designed by aliens with weird dispositions, then the AGI machines they’d create would look like aliens with weird dispositions. It is merely the circumstances of their creation: when it comes to general intelligence, the created will look like the creator they were modeled after.
Generally speaking, to engineer AI, humans are engineering goals defined by the ability to perform to the standard of humans. It may be counter-intuitive, but engineers consider human samples to be the gold standard of training data. Sometimes this is true in indirect ways. For example, Dall-E, the image generation AI, is trained based on examples of human-drawn artwork. Even if it was trained only from photos, it would still be calibrated against human work, as humans are required to shoot and curate those photos.
Since we train AI models by showing sample results produced by human minds, AI is evaluated with respect to how closely it can emulate human results. By virtue of this process, we are engineering AI to behave as closely to humans as possible. The more we improve AI, the closer it gets to that level. At or beyond that level, more calibration will only move it closer to the average of human performance.
If you want to train AI to be better than humans, we’ll need (one would think) training examples of better-than-human performance. But who could generate those examples, before we had the machine to generate it? It’s a catch-22.
Of course, AIs can reason much better with humans from less information. Given the rules of chess, they can quickly become better than humans at chess. Where AIs need humans relates to knowledge (eg, knowledge of the rules of chess). I believe AI values and fundamental axioms are more closely connected to that knowledge which is dependent on human input.
Insofar as AI performs better than humans, it is generally because (A) it can do the same thing as humans, only much faster, and (B) it can do simple functions without error, like a calculator. Give a human a programmable calculator, unlimited memory, and enough time, then assuming the AGI human-plateau model, that human would be able to do everything an AI can do. I don’t want to trivialize that. But it does limit AI in the following way.
Let’s imagine that there are certain ideas that are so complex than a human of non-genius intelligence will never have them, even given 500 years. If my plateau model is true, then early AGIs will also not be able to have those kinds of ideas. In other words, the first AGIs will not be Einsteins.
This strikes at the difference between qualitative and quantitative superiority. A man of average intelligence will never, even if given 500 years, have the same thoughts as Albert Einstein. A hundred mediocre singers will never be able to match the vocal range of one Soprano opera singer. A hundred mediocre programmers will never write the bitcoin whitepaper and corresponding code. Quantitative superiority is about speed and scale. Qualitative superiority is about doing what others cannot do.
The ability to mimic humans and the ability to supplant humans are different. If a task is plug-and-play, ie, it has already been done elsewhere by humans, and we just need to do it again in a new context, that is very feasible for AI. A lot of work that humans do is like that, and that can be automated. However, it’s less feasible for AI to do tasks that are truly novel. I like to think that humans, helped by the ability to draw directly from their experience in the physical world, do novel things all the time. That’s hard to surpass.
6. Even in the present day, we have AI alignment problems, and it has not destroyed society. Future alignment problems will most likely look like what we have, not what you imagine.
I can outline two present day AI alignment scenarios. First, social media algorithms. They are not AGI; they are narrowly intelligent algorithms, often neural networks, tasked with optimizing certain metrics (eg, engagement, watch time). These algorithms have enormous influence over society. This is not a knee-jerk, “Facebook got Trump elected!” You’ve already heard complaints about that. What I’m talking about is more of a Jonah Haidt-style, “Instagram is making us depressed!”
But more than that, I’ve seen internet content creators, small and large, behave is various perverse or extreme ways, the cause of which being an addiction brought about by social media algorithms. These people are being controlled by AI. Yes it is not coerced, in as much as partaking in an addiction is not coerced, but it is literal AI control over humans. What’s more, the AI algorithms don’t care how they affect people’s time, social life, worldview, and behavior. They only care about optimizing a narrow metric.
Another example is technological unemployment. Surely at least some people have already had their jobs automated because of ML. On the other hand, ML has also create enough jobs that it’s not been considered a problem. However, the jobs that ML creates tend to be very high-skill, whereas the jobs at risk of automation to be low-skill. It is possible that in the near future this will create a lopsided economy with abysmal employment prospects for less educated workers despite many unfilled jobs openings for certain positions.
What will an AI alignment apocalypse look like? From the start, words like apocalypse or doomsday create a misleading image, because they cause you to think of the wrong kinds of scenarios. In reality, future AI alignment problems will most likely look similar to existing AI alignment challenges, just to a greater extent.
Doesn’t this contradict what I said before? Doesn’t this mean that AI alignment is definitely a major risk? Well, here is the reason I think otherwise.
People who imagine AI doomsday scenarios are typically imagine it like a sudden disaster. One day, AI is no threat, the next day, it is spelling the end of civilization. However, the point I’m making here suggests a gradualist view. According to the gradualist view, AI alignment scenarios are not stark/binary. It is a problem that starts small and then (possibly) gets worse. But we will notice as it’s getting worse. And it may actually get better, as the intuition of the AI improves.
It is not true that going from mere AI to AGI will cause the first alignment problems, because the first alignment problems are already here, and the effect of that transition is uncertain.
